What It Really Means for Software Development
What Is Vibe Coding?
The term was coined by Andrej Karpathy in early 2025 to describe a mode of software development where the developer describes intent in natural language and delegates the actual writing, refactoring, and debugging to an AI model. Instead of typing every line, you describe what you want, review the output, and iterate. The AI writes. You steer.
In practice, this means using tools like Claude Code or OpenAI Codex to build entire features from a conversation. The developer’s role shifts from writing code to orchestrating it.
By 2026, adoption moved well beyond experimentation. Engineering teams are resolving real bugs, performing database migrations, and building complete APIs with minimal manual intervention. The productivity gains are real and measurable.
How the Market Is Using It Today
Adoption has been faster than most predicted. The JetBrains State of Developer Ecosystem 2025, based on responses from 24,534 developers across 194 countries, found that 85% of developers now regularly use AI tools for coding and development, and 62% rely on at least one AI coding assistant, agent, or AI-powered editor. The tools have moved from novelty to infrastructure.
Developers use AI to generate boilerplate, write unit tests, explain unfamiliar codebases, suggest refactors, and accelerate the parts of the job that are repetitive and well-defined. The more ambiguous and architectural the problem, the less AI contributes without strong human guidance.
At the enterprise level, the conversation has shifted from “should we use this?” to “how do we use this responsibly?” Teams are building internal guidelines around which tools are approved, what code can be sent to external APIs, and how AI-generated code gets reviewed before it reaches production. Organizations that haven’t had this conversation yet are taking on risks they may not fully understand.
How Big Tech Is Using It
The clearest signal that vibe coding crossed from experimentation to production came in February 2026, during Spotify’s Q4 earnings call.
Spotify co-CEO Gustav Söderström stated that the company’s best developers had not written a single line of code since December. The system behind this shift is called Honk, an internal AI development environment built on Claude Code. Instead of manually debugging or building features, Spotify’s top engineers now direct AI agents via Slack that write, test, and deploy code in real time. As Söderström described it: an engineer on their morning commute can tell Claude via Slack to fix a bug or add a feature, receive a new version of the app on their phone, and merge it to production before arriving at the office.
Spotify attributed significant productivity gains to Honk, shipping more than 50 new features and updates to its streaming app in 2025 alone. Spotify serves hundreds of millions of users across multiple platforms and regions, with a complex technology stack that makes this a meaningful reference point. The announcement was made on a regulated earnings call, in front of investors, with named systems and specific timelines.
An internal Meta document obtained by Business Insider in March 2026 shows specific AI adoption targets across different engineering organizations. Meta’s creation org, responsible for building and maintaining core creative experiences, set a goal for the first half of 2026 that 65% of engineers should write more than 75% of their committed code using AI. The company’s Scalable ML team had a February 2026 target of 50% to 80% AI-assisted code. Companywide, Meta set a Q4 2025 goal for 55% of software engineers’ code changes across central product organizations to be agent-assisted, alongside 80% adoption of general AI tools among mid to senior-level engineers. A Meta spokesperson confirmed to Business Insider that the company’s performance program is focused on rewarding impact from AI tools, not just usage.
The question for most engineering organizations is no longer whether to adopt AI coding tools. It is how to do it with appropriate governance, quality controls, and strategic intent.
The Benchmark Question: How Do We Actually Measure This?
Before discussing which models to use, it’s worth understanding how they’re evaluated, because the numbers that appear in announcements don’t always mean what they seem.
The dominant benchmark for AI software engineering today is SWE-bench, introduced by Princeton researchers in 2024. The setup is straightforward: given a real GitHub issue and the full codebase of a popular Python repository, the model must generate a patch that resolves the issue and passes the associated unit tests. No hints about which files to edit. No simplified toy problems. Real repositories like Django, scikit-learn, and matplotlib.
When SWE-bench launched, the best available model, Claude 2, resolved just 1.96% of issues. By early 2026, the leading models exceed 70% on the most widely cited variant, SWE-bench Verified. That trajectory tells an important story about the pace of progress. There is, however, a significant caveat: Verified is likely contaminated, and a newer variant called SWE-bench Pro was designed to address this. The practical implication is simple: when a vendor announces a benchmark score, the first question should always be which variant. Scores on Verified and Pro describe very different levels of real-world capability.
Leading models in 2026
The scores below reflect the SWE-bench Verified leaderboard as of April 20, 2026. All models were evaluated using mini-SWE-agent v2, a minimal bash-only agent implemented in under 100 lines of Python, developed by the SWE-bench team specifically to eliminate scaffold differences between models. Every model gets the same simple setup: a bash terminal and nothing else. No proprietary tools, no special context management, no optimizations. This is what makes the comparison meaningful, and also why these numbers are lower than the scores vendors report using their own optimized agent systems. The same model evaluated with Claude Code or Codex typically scores 5-15 points higher than with mini-SWE-agent v2. These numbers change frequently as new models are submitted. For the latest rankings, check swebench.com directly.
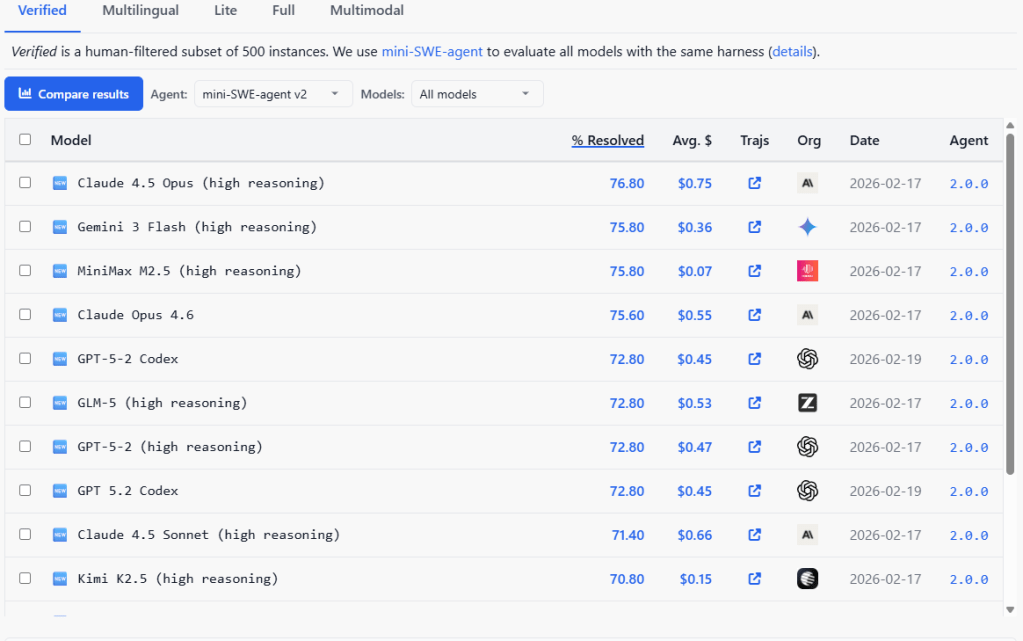
On SWE-bench Verified, Claude 4.5 Opus leads at 76.8% at an average cost of $0.75 per task.Gemini 3 Flash and MiniMax M2.5 follow tied at 75.8%, with a notable difference: MiniMax costs $0.07 per task versus $0.36 for Gemini. Claude Opus 4.6 reaches 75.6%, and GPT-5.2 Codex, GLM-5, and GPT-5.2 all land at 72.8%. Claude 4.5 Sonnet reaches 71.4% and Kimi K2.5 closes the top 10 at 70.8% at $0.15 per task.
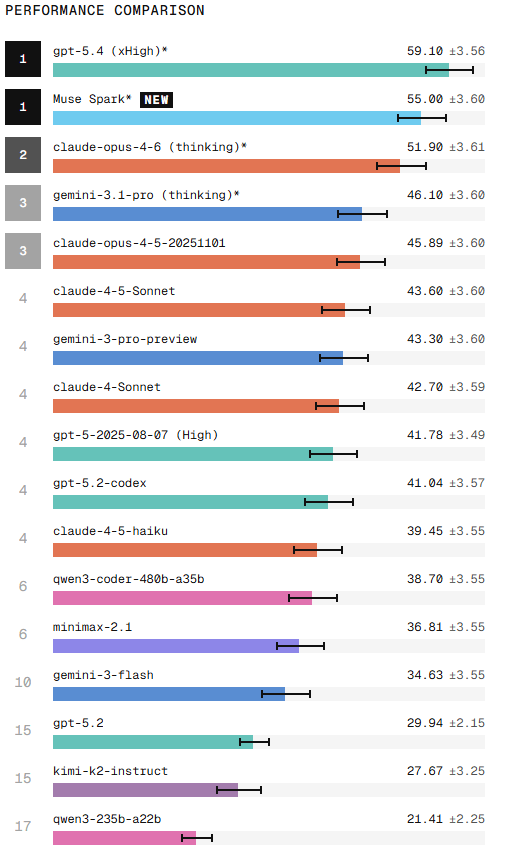
On SWE-bench Pro, GPT-5.4 leads at 59.1%, followed by Claude Opus 4.6 with thinking at 51.9%, Gemini 3.1 Pro at 46.1%, and Claude Opus 4.5 at 45.9%. The remaining models score between 27% and 43%.
An important caveat when reading these two benchmarks together: the model versions are not always the same. MiniMax M2.5 appears in Verified while MiniMax M2.1 was evaluated in Pro.Kimi K2.5 appears in Verified while Kimi K2 appears in Pro. Evaluations were run at differenttimes with different scaffolds. Direct comparisons should be made carefully.
Why benchmark scores should be read with caution
Benchmarks have three structural limitations worth understanding before using them to make decisions.
The contamination problem. AI models are trained on enormous amounts of text from the internet. SWE-bench Verified was published in 2024, which means its 500 tasks, the GitHub issues, the codebases, the correct solutions, have almost certainly appeared in the training data of every model released since then. When a model encounters a task it has seen before, it is not solving a new problem. It is recalling a solution. The benchmark stops measuring reasoning ability and starts measuring memory. OpenAI confirmed this when they audited their own models and found that frontier models could reproduce verbatim solutions for certain Verified tasks. That is why they stopped reporting Verified scores.
SWE-bench Pro was designed to address this. It uses repositories under GPL licenses, which creates legal barriers against including the code in commercial training datasets, and draws from private proprietary codebases that models could not have seen. The result is a benchmark that is harder to game, and significantly harder in absolute terms. Models that score 70-76% on Verified score 27-59% on Pro. The gap between those two numbers is, in large part, the contamination effect.
The agent system problem. A benchmark score does not measure a model in isolation. It measures a model plus the complete system around it: how the model receives the task, which tools it can use, how many attempts it gets, how it navigates files, and how it decides when it is done. The same underlying model can score 23% with a basic setup and 59% with an optimized one. When vendors report benchmark scores using their own proprietary setups, and most do, the numbers are not directly comparable. You are comparing different systems, not different models. SWE-bench Pro addresses this partially by using a standardized setup across all models, which is why its leaderboard is a more controlled comparison.
The metric problem. The benchmark only measures whether the generated code passes predefined tests. A patch that passes the tests but introduces a security vulnerability, adds technical debt, or breaks conventions the tests don’t cover scores the same as a clean, well-reviewed solution. The number tells you nothing about code quality, maintainability, or security.
The trajectory from 1.96% in 2024 to 70%+ in 2026 reflects real progress in model capability. Benchmarks provide a useful general picture of how models compare. But a single number should never be the primary basis for a model selection decision. The most reliable evaluation is running your own tasks, on your own codebase, with your own definition of what a good solution looks like.
Why Claude and Codex Feel Like First Division in Practice
If the benchmarks are converging, why do developers consistently report that Claude and Codex feel qualitatively different for real development work?
Three reasons stand out.
The first is how these models handle ambiguous intent. Vibe coding prompts are rarely precise technical specifications. You describe what you want in natural language, often incompletely, and expect the model to infer the rest. Claude handles vague, underspecified prompts better than most alternatives. Other models, including those with comparable benchmark scores, tend to require more explicit instruction to reach the same output.
The second is context window size and coherence. Claude Code operates with a 1 million token context window. In a green field project that grows over hours of iteration, maintaining coherence across the entire codebase requires holding a lot in working memory. Models with 128k-256k context windows hit limits that are notice able in practice.
The third is ecosystem maturity. The volume of community documentation, examples, prompt engineering guides, and troubleshooting resources around Claude and Codex is orders of magnitude larger than for newer alternatives.
This doesn’t mean newer models aren’t capable. It means the complete system, including tooling, documentation, and community, is part of what you’re evaluating.
Security Problems
AI coding tools introduce two categories of security risk that deserve serious attention from any organization using them in production.
The first is vulnerability propagation in generated code. AI models generate code that compiles and passes tests, but passing tests is not the same as being secure. A December 2025 analysis by CodeRabbit of 470 real-world open source pull requests found that AI-generated code averaged 1.7x more issues per PR than human-written code. Security vulnerabilities were 1.5 to 2x more frequent, and performance inefficiencies appeared 8x more often. The model doesn’t know your threat model. It optimizes for code that works, not code that is safe.
A developer who understands security can review generated code critically. A developer who cannot is shipping vulnerabilities at AI speed. The productivity gains of vibe coding can become a liability if code review practices don’t evolve alongside adoption.
The second risk is more structura. These tools have access to your entire development environment. When you use Claude Code, Codex, or Cursor in agent mode, the tool reads your files, your environment variables, your configuration, and potentially your credentials. That context is sent to external APIs operated by Anthropic, OpenAI, or Microsoft. For most consumer applications this is acceptable. For organizations working with proprietary
codebases, regulated data, or sensitive infrastructure, this is a significant exposure that requires explicit policy decisions, not assumptions.
The question is not whether these companies are trustworthy. The question is whether you rorganization’s security posture and compliance obligations permit sending that context outside your network boundary.
The Impact on Developer Roles and the Junior Pipeline
The productivity gains from AI coding tools are real, and the market is adjusting accordingly. Companies are hiring fewer junior developers, expecting existing engineers to cover more ground with AI assistance, and concentrating demand at senior levels where judgment and architecture matter more than raw output. A survey by Hired.com found that job postings requiring experience with AI coding tools increased by 340% between January 2025 and January 2026, while postings for pure implementation roles declined by 17%.
This creates a structural problem that the industry hasn’t resolved. If junior developers aren’t being hired at scale, how does the next generation of senior developers form?
Senior engineering expertise is not simply accumulated knowledge. It is pattern recognition built through years of debugging, shipping, maintaining, and breaking things in production. That experience has to come from somewhere. AI tools can accelerate certain parts of the learning curve, but they cannot substitute for the judgment that develops through direct exposure to failure and consequence.
The developer who relies on AI to generate code without understanding what it generates is not developing that judgment. They are building a dependency. When the AI produces something subtly wrong, and it does, regularly, the developer without deep understanding of the underlying systems cannot catch it.
The Education Question
If a student today learns to code primarily through AI assistance, a legitimate question emerges: are they learning to program, or learning to prompt?
Understanding how systems behave, why they fail, and how to reason about complexity requires direct exposure to failure. You build that understanding by writing bad code, debugging problems that don’t have obvious solutions, and dealing with the consequences of architectural decisions over time. AI tools can short-circuit that process. A student who generates a working solution without understanding it has not learned to solve the problem. They have learned to delegate it.
This creates real challenges for educators. How do you teach algorithmic thinking when the algorithm can be generated on demand? How do you evaluate understanding when the AI can produce the answer? How do you build the foundation of knowledge that enables systematic thinking about software at scale?
There are no clean answers. The most likely outcome is that baseline expectations for software developers shift, with less emphasis on syntax and boilerplate, and more on architecture, security, and evaluation of AI output.
Open-Weight Models and On-Premise Alternatives
For organizations that cannot send code to external APIs, due to regulatory requirements, sensitive IP, or simply because token costs at scale become prohibitive, self-hosted open-weight models are an increasingly viable option.
MiniMax M2.5 leads open-weight models on SWE-bench Verified at 75.8% using the standardized mini-SWE-agent v2, at an average cost of $0.07 per task via API, roughly 10x cheaper than Claude Opus. Available as open-weight with a modified MIT license. The full model requires substantial GPU memory to self-host, but the API pricing makes it accessible without infrastructure investment.
Qwen 3.5 (Apache 2.0, Alibaba) reaches 76.4% on SWE-bench Verified with the 397B variant. The more practical option for self-hosting is the Qwen 3.6-35B-A3B, which uses a Mixture of Experts architecture with only 3B active parameters per token, reaching 73.4% on Verified while fitting on a single consumer GPU. Apache 2.0 license means no commercial restrictions.
DeepSeek V3.2 (MIT license) reaches 73.1% on SWE-bench Verified. Like Qwen, it uses a MoE architecture, 685B total parameters but only ~37B active during inference. The MIT license is the most permissive available, with no commercial restrictions. Via API it costs around $0.30/$1.20 per million input/output tokens, making it the cheapest frontier-level option for high-volume use.
Self-hosting: what you actually need
The single most important constraint for running these models locally is GPU VRAM, the model weights must fit in GPU memory for acceptable speed. Here is a practical guide by hardware tier:
Consumer GPU (24 GB VRAM), RTX 4090 or RTX 3090. Runs 4-bit quantized models up to ~32B parameters comfortably. The best choice at this tier is Qwen 3.6-35B-A3B (3B active params) or DeepSeek distilled variants. Expect 20-40 tokens per second.
Professional GPU (40-80 GB VRAM), A100 40GB or H100. Runs 70B models quantized or 32B at full precision. Covers most production use cases for a single-team deployment.
Multi-GPU (multiple H100/H200), required for running MiniMax M2.5 or DeepSeek V3.2 at full precision. The full DeepSeek V3.2 needs approximately 8× H200 GPUs. For most organizations, accessing these models via API is more practical than self-hosting.
Inference software
Ollama is the simplest starting point. A single command installs and runs any supported model with automatic quantization. Suitable for individual developers and small teams exploring localmodels.
vLLM is the standard for production serving. It handles multiple concurrent users efficiently and exposes an OpenAI-compatible API, making it easy to swap with existing integrations.
Text Generation Inference (TGI) from Hugging Face is a strong alternative to vLLM with straightforward Docker deployment and deep integration with the Hugging Face model ecosystem.
Model Routing: Managing a Portfolio of Models
The business case is straightforward. A frontier model like Claude Opus charges around $25 per million output tokens. A capable mid-tier model might cost $1-3. Routine tasks like generating documentation, writing boilerplate, and answering well-defined questions don’t require frontier-model capability. Routing them to cheaper alternatives while reserving expensive models for complex reasoning can reduce AI infrastructure costs significantly, without meaningful quality degradation on simpler tasks.
The principle is well-established in practice: not every request needs the most expensive model. The harder question for software engineering specifically is where to draw the line. Code tasks tend to have longer context, tighter correctness requirements, and steeper quality cliffs between model tiers than general tasks like Q&A or summarization. The right routing strategy for a given team depends on their workload, and the only reliable way to validate it is to test on their own tasks.
The main options in 2026
Managing a portfolio of models requires thinking about two distinct layers: the gateway layer, which controls how requests are routed to different models, and the agent layer, which controls how those models interact with your codebase and development environment. These layers are complementary and can be combined.
Gateway layer
OpenRouter is the simplest entry point. A single API key provides access to 400+ models from multiple providers, with consolidated billing and automatic failover. It charges approximately 5% markup over provider prices. Best for teams that want rapid model iteration without infrastructure overhead.
LiteLLM is an open-source Python proxy that presents a unified OpenAI-compatible interface to 100+ providers. It supports per-team and per-project budget limits, fallback chains, and detailed usage tracking. Unlike managed services like OpenRouter, it requires self-hosting: an initial setup effort to install, configure authentication, connect providers, and integrate with existing systems, followed by ongoing infrastructure maintenance in production. The tradeoff is worth it for organizations that need data sovereignty or fine-grained cost control, and less so for smaller teams where the operational overhead outweighs the benefits.
Bifrost (open-source, written in Go) is purpose-built for production performance, with 11 microseconds of overhead at 5,000 requests per second, significantly faster than Python-based alternatives. It includes semantic caching, automatic failover, RBAC, and SSO. Best for teams where latency and governance are critical requirements.
Agent layer
While gateways manage which model receives a request, agents determine what the model can do with it. Coding agents connect a model to your development environment: they read and edit files, run terminal commands, navigate codebases, and execute multi-step tasks autonomously. The model reasons and the agent acts.
Cline is an open-source coding agent that runs inside VS Code. It supports any model via API, which means it can point to a self-hosted model, a gateway like LiteLLM, or a provider directly. It has no vendor lock-in and gives full visibility into every action it takes.
Cursor is a code editor built around AI assistance. Unlike Cline, it is a standalone application rather than an extension, with tighter integration between the editor and the model. It uses its own model routing internally but also supports bring-your-own-key configurations.
Aider is a terminal-based coding agent designed for git-integrated workflows. It works with any OpenAI-compatible API, supports multiple models simultaneously, and is particularly effective for targeted edits across multiple files.
How the layers connect
A practical architecture for a mid-sized engineering organization combines both layers, a gateway like LiteLLM sits between the agent and the model providers, enforcing budget limits and routing decisions, while developers interact through Cline or Cursor pointed at the gateway rather than directly at providers. This gives the organization cost control and model flexibility without changing the developer experience.
Within that setup, routine tasks and high-volume automation go to self-hosted open-weight models. Standard development tasks go to mid-tier API models like Claude Sonnet or Gemini Flash. Complex architecture decisions, debugging of subtle failures, and high-stakes code review go to frontier models. And any request involving potentially sensitive data is routed to on-premise infrastructure that never leaves the network.
Conclusion
It is a genuine productivity tool that is changing what developers spend their time on, and raising legitimate questions about security, talent development, and organizational governance that the industry is still working through.
The developers and organizations that will benefit most are those who approach these tools with the same rigor they would apply to any significant infrastructure decision: understanding what the tools actually do, where they introduce risk, how to evaluate their output critically, and how to build governance around their use.
Benchmark scores matter, but they measure one dimension of a complex system. The real questions for any team adopting AI coding tools are more practical. Does the output get reviewed by someone who can catch what’s wrong? Do your security policies account for what gets sent to external APIs? Is your junior talent still developing real engineering judgment, or building a dependency? How do you know the difference?
These are not reasons to avoid the tools. They are reasons to use them thoughtfully.
References
JetBrains State of Developer Ecosystem 2025:
https://blog.jetbrains.com/research/2025/10/state-of-developer-ecosystem-2025/
Spotify Q4 2026 earnings call coverage (TechCrunch):
https://techcrunch.com/2026/02/12/spotify-says-its-best-developers-havent-written-a-line-of-code-since-december-thanks-to-ai/
Meta internal AI adoption targets (Business Insider):
https://www.businessinsider.com/meta-ai-push-employee-goals-tool-adoption-2-026-3
SWE-bench Verified leaderboard:
https://www.swebench.com/
SWE-bench Pro leaderboard (Scale AI):
https://labs.scale.com/leaderboard/swe_bench_pro_public
Stanford study on developer employment: MIT Technology Review, December 2025:
https://www.technologyreview.com/2025/12/15/1128352/rise-of-ai-coding-developers-2026/

Leave a comment